William P. Birmingham[1], Karen M. Drabenstott[2], Carolyn O. Frost[2], Amy J. Warner[2], and Katherine Willis[2]
[1] Advanced Technology Laboratory, College of Engineering, University of Michigan, Ann Arbor, MI 48109-2110, wpb@eecs.umich.edu
[2] School of Information and Library Studies, 550 East University Avenue, Ann Arbor, MI 48109-1092 USA, {karen.drabenstott, carolyn.frost, amy.warner, kathy.willis}@umich.edu
Abstract
This paper uses the term "digital library" as a generic name for dynamic, federated structures that provide intellectual and physical access to the growing world-wide networks of information encoded in multimedia digital formats and examines research toward the broad goal of personalized harvesting in the information wilderness organized around agency-based architecture. Beginning from the perspective of the desktop, the researchers will explore the creation and evaluation of an architecture consisting of user interface agents, query processing agents, mediators, ontologies, and collection interface agents.
Although much of the research will be generic with respect to the information subject area, the testbed will focus on the subject domain of earth and space science. User communities for the testbed will include expert researchers, graduate, undergraduate, and high school students, and the general public. The research team will build a microcosm of content levels and media types, including page images, structured documents (SGML), interactive, compound documents and real-time interaction with real-time scientific data. Economic and intellectual property issues will also be considered in the design. Evaluation will be featured on a continuing basis.
Keywords: Agent architectures, Distributed systems, Information retrieval, Search algorithms
1. Project Overview
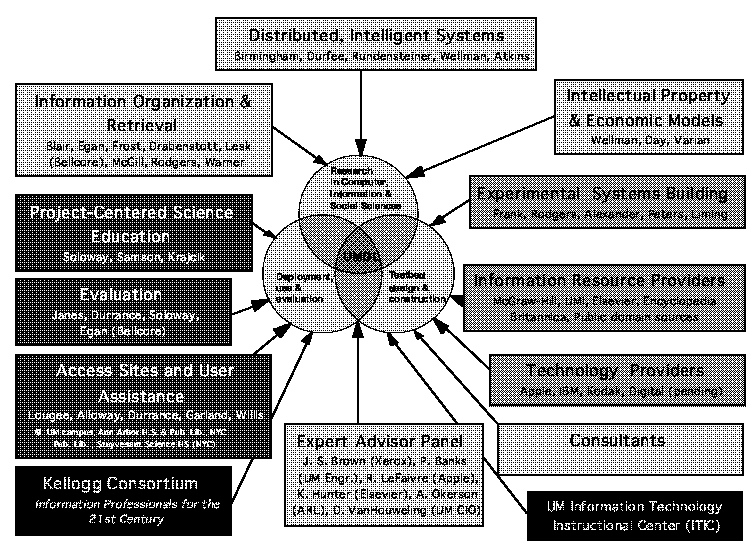
A multi-disciplinary team at the University of Michigan proposes coordinated research and development to gain insight into the creation, operation, and use of large scale, continually evolving digital libraries (see Figure 1). We use the term "digital libraries" as the generic name for federated structures that provide humans both intellectual and physical access to the huge and growing worldwide networks of information encoded in multimedia digital formats.
The fundamental mission and centuries-old tradition of libraries and the library profession has been to provide intellectual and physical access to and preservation of the human record. Although this fundamental mission will continue to be vitally important, the manner in which libraries fulfill it is being radically altered by the sudden change in the physical basis (electronic, optical, magnetic) for information representation [3]. This shift to "de-massified" representation will alter the structure and process by which humans create, find, use and re-use the information they need and want. In particular, the digital library has the potential to:
* Provide information any time and any place,
* Provide access to collections of multimedia information built upon the integration of text, image, graphics, audio, video (and other continuous media),
* Support user-friendly personalization/ customization of information access and representation, including support for "harvesting" relevant information and protection from information overload,
* Be the heart of new technology-mediated structures to radically enhance collaborative intellectual activities such as research, learning, and design by reducing barriers of distance (geographic and organizational) and time.[1]
Figure 1. Constituent Competencies for the UMDL Research Project
The realization of these potentials requires fundamental research and development of user-centered pilot projects to address a complex array of technical and socioeconomic issues. We have brought together a unique team, with demonstrated competence in the broad areas of research, system building, and end-user service necessary to do this. Team participants are faculty, research staff and students from the Department of Electrical and Computer Engineering, the School of Information and Library Studies, the Department of Atmospheric, Ocean and Space Sciences, the University Libraries, the Computer-Aided Engineering Network, the Information Technology Division, Ann Arbor Public Schools and Library, the New York Public Library and Stuyvesant Science High School, Bellcore, McGraw-Hill, UMI, Elsevier, Encyclopedia Britannica, IBM, Apple, and Kodak.
Although we will build a complete system, we will focus on two primary areas: (1) at the front-end, we will offer users customized (adaptive) query and viewer facilities to support intellectual access to information, and (2) at the back-end, we will explore approaches to rapid federation of diverse information resources into the digital library. These functions will be brought together in an agent-based architecture, connecting front-end, back-end, and intermediate services, such as search, retrieval, and document structuring facilities.
We intend to build an experimental system -- the University of Michigan Digital Library (UMDL) -- as the basis for operational digital-library systems. We have obtained significant collections and vendor support for this project. In addition to relevant research and system-building competency, we possess two other strengths. First, we have strong bonds between the computer-science and information-technology communities and the information and library science academic community. The latter includes various types of libraries (academic, public, school, special) and several publishers. Second, we have the opportunity to link this project with support from the Kellogg Foundation. This linkage will enable us to radically broaden and revise the curriculum in information and library science/studies (ILS) schools to produce the leadership that will design, develop, promote, and manage digital libraries.
2. System Architecture
2.1. Introduction
The purpose of this paper is to overview the research component of the UMDL. In pursuing our research, we will be guided by the practical context in which the library is to be developed and deployed. In particular, we will address issues arising from the diversity of user groups, computational environments, and information collections comprising the UMDL. Characteristics of digital libraries posing special challenges include:
* Variance in user needs and sophistication,
* Diversity in hardware performance,
* Large, both in size and number, information resources that are physically distributed,
* Heterogeneous types of information resources created by a variety of groups,
* Multimedia data types,
* The need for extensibility to add new collections (e.g., a new database system) as well as new data types (e.g., voice).
A major challenge of digital libraries is avoiding information overload. The ever-growing availability of data can reduce the amount of effective information that users can retrieve from the system in an acceptable amount of time and with reasonable ease. Our goal is to enable users truly to profit from the amount of available information by providing them with tools that simplify the retrieval of meaningful information from this mountain of data.
Several ramifications of these challenges will influence the UMDL's design:
* The UMDL will be organized as a distributed system. Information resources will be managed by computational agents. The network will include agents that perform on behalf of users (e.g., processing search requests), information sources (e.g., multicasting their contents), or the network itself (e.g., reorganizing ephemeral communication links among agents).
* The network must be flexible enough to allow information resources to be placed on or taken off the network without adversely affecting the network. (We envision literally millions of information resources eventually on the network.) We will achieve this by enforcing communication protocols among agents in the network for the dynamic construction of processing strategies, rather than supporting hard-coded connections. This will allow individual information sources and user interfaces to be engineered by local groups as they see fit.
* The vastness of the amount of information on the network can render undirected searching impossible. To ensure an efficient search, we must develop intelligent, well-informed search strategies customized to the true needs of the user, and we must also exploit the structure of information on the network. The latter must include two categories of structure. First, hierarchical, bibliographic structures must be imposed on the collections of the information sources to indicate which ones may have the information being sought. Second, individual information sources themselves must be structured to facilitate an efficient local search.
* As the network agents are autonomous, they will need to make decisions about whether to participate in a search, whether to return information being sought, and so forth. It is critical that these agents base their decisions on some metric of value that considers both the public good and incentives for individual participation. Such economic models of decision-making will be used to coordinate activity in the network.
* The information sources will contain intellectual property, therefore the network must provide mechanisms to both protect this property (from unauthorized copying, for example) and to collect fees for its usage.
* As the size of the network grows, it will be difficult to enforce standards of information source architectures. Therefore, we must standardize communication protocols, and not the architecture of information sources.
Our system architecture, described in the remainder of this section, will be designed primarily to afford flexibility in addressing the diversity of requirements and resources described above. Our broad goal is to develop a new paradigm for integration of autonomous, disparate systems that is truly distributed, yet performs seamlessly. A major challenge is to share information across the UMDL, while maintaining the autonomy of individual collections. In particular, consider that individual information-source providers (third parties to those developing and maintaining the digital library), working without interaction from other providers, need to be able to place their information resources in the network without requiring them to necessarily understand details of the overall library system. The same will apply to third parties producing user interfaces.
2.2. Agent-Based Architecture
UMDL will be organized as a distributed system consisting of information sources, user interfaces, and sets of processing agents. Most of the actual services required from the digital library system will thus be performed by these information agents. In general terms, these services are concerned with translating a query or some other expression of a user's need into a delivery of information meeting that need. More specifically, we can classify the information agents in our system as responsible for the following tasks:
* Processing user queries and displaying retrieved information,
* Searching, filtering, and summarizing large volumes of data,
* Translating or passing on search requests to databases or other agents,
* Maintaining metadata about a particular data repository,
* Monitoring usage patterns and information changes to initiate reorganization of data and notification of users.
Figure 2 illustrates, at a very high level, the UM Digital Library, linking several users through their User-Interface (UI) agents to collections through Collection-Interface (CI) agents. In a simplistic system, the UI agents and CI agents could be networked together, allowing UI agents to query collections directly, either sequentially or in parallel. There are many problems with this simple solution, such as the duplication of effort in having UI agents determine the subset of CI agents needed to service a particular request, or the complexities of terminating the search once a CI agent has successfully answered a user query.
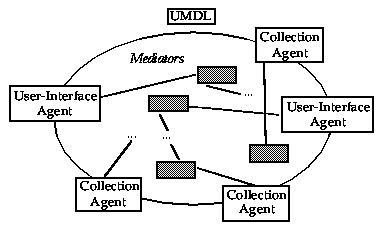
Figure 2. A federated agent architecture
Embedding specialized information agents (besides the UI and CI agents) into the architecture to act as mediators between users and collections can alleviate these problems, and provide additional useful services to library users and contributors of information to the library. Different types of mediating agents for finding, processing, and delivering information are distinguished by their specific knowledge and expertise. Some examples of potential agent capabilities include:
* Understanding general requirements, as well as particular requests, of users,
* Executing effective search strategies over the network,
* Possessing effective strategies for processing searches over the network,
* Summarizing and displaying information in various ways,
* Understanding the contents and organization of particular collections,
* Understanding the relations among collections, data formats, etc.,
* Understanding the availability, capabilities and usage of network resources,
* Gathering usage patterns of particular users or user groups,
* Possessing alternative methods for summarizing and displaying information,
* Understanding capabilities and effectiveness of other agents,
* Understanding the particular domains of inquiry.
The knowledge and computational resources available to particular information agents dictate the range of information services they can provide to users or other agents. Each individual service offered by an information agent is a building block for constructing complex information-processing strategies. Combinations of cooperative agents can collectively implement the more complex tasks required of the digital-library system, such as information-storage (e.g., caching and indexing schemes), access-plan strategies (e.g., browsing options and traversal paths), and so on. Realizing the benefits of populating the digital library architecture with a community of diverse information agents will require the agents to team dynamically to provide a particular information service on demand [4]. In the following sections, we describe a representative set of agents that comprise the digital library and the general mechanisms for coordination and communication that we will employ.
3. Agents
3.1. Introduction
Our development of a comprehensive agent-based architecture will focus on the construction of particular agents and protocols:
1. User-interface agents for both on-demand and continuous modes of operation, including an interviewing agent to help lead digital library users to the best information for their needs regardless of the type or genre of the resource.
2. Supporting query-processing agents, incorporating linguistic retrieval, and providing information integration.
3. Mediators to support the interactions between users and collections to assist in fulfilling queries, organizing information, and allocating resources to satisfy a community of scholars. Economic coordination mechanisms will provide a framework for dynamically allocating resources across information-processing activities.
4. Ontologies and protocols to federate any collection of independently generated information sources in a common language for describing contents without detailed information about access mechanisms, organization, or any other implementation-specific issues.
5. Collection-interface agents maintaining the links between autonomous data repositories and the rest of the system. These agents will translate query requests, map between data types and formats, resolve schema inconsistencies, etc.
3.2. User-interface Agents
The UMDL's user interface agents will provide search strategies to the user accessing UMDL. As an example, we will develop a class of user-interface agents, called an Interviewing Agent (IA), that strives to lead digital library users to the best information for their needs regardless of the type or genre of the resource. It will also serve as a helpful companion that users can call on for guidance and instruction during their navigation through the federated network or examination of digital resources.
The IA will model the described behavior of information seekers (e.g., high school, undergraduate, graduate researchers) according to definable characteristics and styles, as well as discipline-based methodologies. We plan to interview and study this broad base of users to design the required search strategies. The IA will query users about various parameters of their search, (e.g., intended use, time constraints, familiarity with their topics), and pass this information on to the agents it deems appropriate for further processing.
3.3. Query-Processing Agents
The development of query paradigms that allow users to retrieve the desired material with ease by processing complex requests in this distributed environment is a key research problem. Traditionally, query-optimization techniques determine a fixed execution strategy for a query by evaluating and comparing all information given in the metadata, e.g., availability of indices, size of data sets, etc. In the UMDL this will become a much harder problem because the query optimizer will have to make decisions with incomplete information (e.g., without studying all possible metadata servers). More importantly, the query processor will have to incrementally adjust the query execution plan depending on hit ratios, quality of partial results, etc. In the UMDL, this sort of information will be distributed among those agents expert in the various repositories and access techniques, the so-called metadata agents. We will develop strategies to control the parallel spawning of query requests to different metadata servers.
Much of the information in the digital library will consist of documents and representations in natural and controlled language. Problems with this include not only the intrinsic problems posed by language used in a given database, but also by both the quantity and heterogeneity of the information that will be searched and integrated across multiple collections. The identification and construction of linguistic techniques builds upon prior research in manipulating the surface structure of documents and queries to build linguistic capabilities into an information-retrieval system [10, 11, 12]. These methods make use of the existing surface structure found in documents and queries, as well as the structure and content available in already existing controlled vocabularies. In terms of the overall system architecture, query agents will make use of linguistic techniques to filter and refine large sets of documents.
3.4. Mediators
The purpose of mediators is to support the interactions between users and collections to assist in fulfilling queries, organizing information, and allocating resources to satisfy a community of users. For example, mediators in the network will keep track of published material, maintaining a directory of information sources (e.g., metadata) as they dynamically evolve, and supplying information about sources to help. Typically, there will be many such mediators, hierarchically arranged and with redundant knowledge, to avoid the contention and single-point-of-failure pitfalls of centralized directory services. These hierarchies must dynamically reconfigure themselves as hosts and links fail and as the load on them changes.
Interactions among mediators will resemble a cooperative problem-solving effort among a diverse set of specialists [5], where the problems to be solved, the expertise of the specialists, and the population of specialists can all change over time. To provide this functionality, we will draw on a variety of techniques for distributed problem solving, organizational self design, coordination theory, and distributed artificial intelligence [2]. For example, the process of query decomposition, subquery allocation, and result synthesis can be cast as a contracting arrangement among query processors [9]. Implementation of such techniques in the digital library, however, poses an exciting research challenge because of its dynamic nature. For example, decisions about how best to decompose queries must be based on what collections are likely to be available to respond to queries. Consequently, the decomposition process itself may require communication among mediators to first determine reasonable decompositions, followed up by further communication to then allocate subqueries and collect results.
Directing the activities of mediators is essentially a problem of resource allocation. The alternative information services offered by mediators are competing economic activities. Information agents dynamically connect with each other as opportunities arise for mutually beneficial exchanges. The collections provide the ultimate "raw materials" in this process, whereas the end users are the ultimate consumers of the "finished goods." The mediator agents bridge the gap by bringing to bear knowledge, processing, storage, or other computational resources to improve in some way the expected value of the information as it passes along the chain from agent to agent. Our implementation of virtual markets in information services will be based on the idea of "smart auctions" proposed for smooth allocation of bandwidth on the Internet [7]. The mechanisms for managing multiple, interacting markets will be based on our previously developed "market-oriented programming" system [13].
3.5. Ontologies and Protocols
Central to federating any collection of independently-generated information sources, or databases, is a common language for describing contents without detailed information about access mechanisms, organization, or any other implementation-specific issues. The description of the content, in a sense, is a declaration of what is; this is commonly called an ontology. The ontology, because it must be communicated, is described in some (semi) formal language, facilitating concise and thorough statement of the contents [6, 8].
The ontological approach, therefore, concentrates on defining the following:
* Content-description language: The terms and data must be precisely described in a commonly accepted definition: this is the ontology. The ontology is similar to a data dictionary in database systems, except that it describes the meaning of terms in general, not their representation within this particular DBMS.
* Interchange protocols: As an ontology is a description of what exists in a domain or database, it does not perform any actions per se. Rather, actions occur through protocols. The protocols we will develop as part of UMDL will have the same philosophical basis as ontologies: they will describe services without specifying how they are to be done. Furthermore, these protocols will operate on top of network protocols that describe how to move bits through wires (e.g., TCP/IP) or how to form and interpret blocks of data (e.g., Z39.50).
Interchange protocols will define the full range of activities that can be performed in the UMDL and will apply primarily to mediators and collection agents. By insulating information sources and interfaces from the details of the operation of the network, they are easier to construct and to maintain. Furthermore, we can control their actions, adding security to the network.
3.6. Collection-interface Agents
In our distributed-agent paradigm, queries will eventually be submitted to local information repositories to execute elementary requests on the actual information sources. In order for an information source to participate effectively in the network, it will be assigned a dedicated Collection Interface (CI) agent, responsible for maintaining a link between the repository and the rest of the system. These agents will be capable of translating query requests, mapping between data types and formats, resolving schema inconsistencies, etc. Collection types to be explored include page images, structured documents (SGML), general image collections, and some audio and video.
We focus here on two particular capabilities that CI agents will possess in a digital library. The first capability is to use knowledge supplied by document and domain specialists about the structure of the documents or other information sources, or both, to characterize formats and contents to support queries and browsing. In general, this amounts to expertly guided structuring and organization of the documents and other information resources. The second capability is a more dynamic structuring activity, based on usage patterns, into (possibly transient) virtual collections.
One important task will be to organize image and text data so content in different collections and formats can be intelligently located, quickly retrieved, and easily reused in unanticipated and arbitrary ways. For large, complex collections, conventional retrieval terms will need to be supplemented by some form of knowledge representation, which will be used to segment the search space so agents need apply brute force techniques only in areas where probability of success is high [1].
One simple way of capturing knowledge representation in a digital-library collection will be to associate abstracts and reviews of works with items, separated from content. In addition to information about structure that the information source will provide to its CI agent, we must also investigate what metadata each source should make available, as well as which modeling techniques should best be used to describe this metadata. Metadata will include a description of the content of the database (schema), available index strategies and access methods, the integrity mechanisms enforced, and other information for administrative purposes. A metadata agent will then be in charge of posting a comprehensive description of the collection to the digital library system, representing a wrapper between the local information source and the rest of the system.
3.7. Design and Construction of a Testbed
UMDL will be focused and grounded by the goal to design, construct, deploy, and evaluate a testbed. Although much of the research will be generic with respect to the information subject area, our testbed will focus on the subject domain of earth and space science (ESS). The choice of ESS was motivated by the following considerations: (1) significant expertise and level of activity in this area at the University (Atmospheric, Oceanic, and Space Sciences, and university-wide global change and environmental studies activity); (2) availability of rich, multimedia special collections (real-time and archival) on campus and through government sources (e.g. NASA) sites; (3) the broad, general appeal of this area and its fit to existing research activities in learner-centered high school science education; and (4) linkage with the Upper Atmospheric Research Collaboratory Project (UARC).
As part of this proposal, the University of Michigan plans a comprehensive deployment activity on- and off-campus. Partnerships have been established with publishers and users that will allow us to undertake testing and evaluation of the research proposed under realistic user conditions with a large, representative collection. The fact that we have these relationships established, combined with the existing development of an image-based digital-library system (DIRECT) already in place at the University, will allow us to begin initial deployment of the testbed immediately.
We will start deployment of the testbed with a significant advantage: a small software-development project at Michigan, DIRECT (Desktop Information Resources and Collaboration Technology), has produced a prototype digital-library system for image-based documents. Funding for DIRECT has come from Digital Equipment Corporation and internal University funds. The initial deployment of DIRECT has been undertaken with a journal set provided by Elsevier Science Publishers under its TULIP (the University Licensing Program) initiative.
4. Deployment, Use and Evaluation
Testbed users will include expert researchers, graduate, undergraduate, and high school students, and the general public. We will build a microcosm of content levels and media types ranging from page images to interactive, compound documents and real-time interaction with real-time scientific data, replays of its collaborative sessions, and human expertise. We will also address issues about how users add content to the UMDL.
Usage will be monitored both for any billing needs and anonymously for usage studies and research. Usage statistics will be fed back to the developers and user-studies groups, who will in turn suggest changes, improvements, and new features for UMDL, which, in turn, will require further testing. By using this iterative process throughout the project, UMDL will evolve to both incorporate new research results and to meet the changing needs of the user community.
The UMDL will enable students to explore questions in ways that would be exceedingly difficult, if not impossible, with current resources. For example, students will have access to the same data as the researchers, as well as some access to the scientists themselves. No longer must students rely on minimalist summaries in outdated textbooks. Taken together, the UMDL will provide an information infrastructure that should enable students to develop inquiries into timely, proactive, and authentic -- and hence, motivating -- scientific questions.
Critical to the exploitation of these resources will be ongoing programs of training, user assistance, and outreach to promote use of the digital library. Closely associated with user support will be the ongoing development of the collection of information resources through continued partnerships with information providers, including commercial, governmental, or academic sources. User-support structures envisioned for this project will bring together these themes of technical assistance, user skill development, and responsiveness to user needs both in terms of tapping existing information resources and the development of future resources.
5. Summary
The primary characteristics of a digital library are that it should provide physical and intellectual access to a highly distributed, heterogeneous collection of information resources. Access should be independent of time and distance, and should be flexible and personalized to the individual. Ultimately, it should facilitate new, collaborative ways of learning, gathering information, and doing research. The University of Michigan Digital Library Project is investigating methods of achieving these goals through a distributed, federated architecture, using agents that embody knowledge about collections, users, and query processing methods, as well as mediation procedures to coordinate interactions among them. Our goal is to efficiently guide the user's search toward the best available resources, and avoid the problem of overwhelming the user with too much information. We will pursue this goal in the context of an operational system, continuously evaluated with real users.
In order to carry out this research program, the University of Michigan has assembled a large, multi-disciplinary research team consisting of software engineers, computer and information scientists, economists, librarians, subject specialists, and corporate and academic sponsors. We believe that this approach will enable us to tackle key problems -- technical, organizational and economic -- of the digital library.
Acknowledgments
Members of the UMDL Project Team are: Ken Alexander, James E. Alloway, Daniel E. Atkins, William P. Birmingham, David C. Blair, Colin Day, Karen M. Drabenstott, Edmund H. Durfee, Joan C. Durrance, Randall L. Frank, Carolyn O. Frost, Kathleen Garland, Joseph W. Janes, Michael E. Lesk, Wendy P. Lougee, Gregory R. Peters, David L. Rodgers, Elke A. Rundensteiner, Elliot Soloway, Hal R.Varian, Amy J. Warner, Michael P. Wellman, and Katherine P. Willis.
References
[1] Blair, D. C. 1990. Language Representation in Information Retrieval. Amsterdam: Elsevier Science Publishers.
[2] Bond, A. H., and Gasser, L. 1988. Readings in Distributed Artificial Intelligence. Morgan Kaufmann Publishers, San Mateo, CA.
[3] Drabenstott, K. M. 1994. Analytical Review of the Library of the Future. Council on Library Resources, Washington, DC.
[4] Darr, T. P., and Birmingham, W. P. 1993. Automated Design for Concurrent Engineering University of Michigan, Technical Report No. CSE-TR-174-93, Ann Arbor, MI.
[5] Durfee, E. H., Lesser, V. R., and Corkill, D. D.. 1989. Coordination of Distributed Problem Solvers. In Handbook of Artificial Intelligence, A. Barr, P. R. Cohen, and E. A. Feigenbaum, eds. Reading MA: Addison-Wesley, 83-137.
[6] Gruber, T. R. 1993. A Translation Approach to Portable Ontology Specifications. Knowledge Acquisition 5, 2, 199-220.
[7] MacKie-Mason, J. K., and Varian, H. R. 1993. Pricing the Internet. Public Access to the Internet. JFK School of Government, Harvard University, Cambridge, MA.
[8] Runkel, J. T., and Birmingham, W. P. 1994. Solving VT by Reuse. In 8th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop, B. R. Gaines, M. A. Musen, and J. H. Boose, eds.
[9] So, Y.-P., and Durfee, E. H. 1992. A Distributed Problem-Solving Infrastructure for Computer Network Management. International Journal of Intelligent and Cooperative Information Systems 1, 2, 363-92.
[10] Warner, A. J. 1990. A Linguistic Approach to the Automatic Hierarchical Organization of Phrases. In Proceedings of the 53rd ASIS Annual Meeting, (Toronto, Nov.) D. Henderson, ed. Medford, NJ: Learned Information, 220-7.
[11] Warner, A. J. 1992. A Linguistic Analysis of Variant Expressions in Medline. Proposal funded by the National Library of Medicine.
[12] Warner, A. J., and Wenzel, P. H. 1991. A Linguistic Analysis and Categorization of Nominal Expressions. In Proceedings of the 54th ASIS Annual Meeting, (Washington, Oct.) J-M. Griffiths, ed. Medford, NJ: Learned Information, 186-95.
[13] Wellman, M. P. 1993. A Market-oriented Programming Environment and its Application to Distributed Multicommodity Flow Problems. Journal of Artificial Intelligence Research 1, 1, 1-23.
Last Modified: