Richard M. Tong and David H. Holtzman
Advanced Decision Systems,
division of Booz, Allen & Hamilton, Inc.
1500 Plymouth Street, Mountain View, CA 94043
Abstract
Booz, Allen & Hamilton has developed a knowledge-based approach to "mediated" cross-database access that uses an object-oriented knowledge representation to enable the user to construct detailed models of the retrieval domain of interest. The Booz, Allen & Hamilton system that implements these ideas is called MINERVA and currently uses two kinds of mediators to support access. "Query Mediators" first transform user queries into a series of finer-grained information requests using the knowledge-base of retrieval models, and then probabilistically combine and evaluate the responses from the individual sources. "Source Mediators" first transform the fine-grained requests from the Query Mediators into source specific requests using local knowledge of the sources and their information characteristics, and then transform the responses from the specific sources into a form that the Query Mediators can use for combination and evaluation.
Keywords: Heterogeneous databases, mediated systems, distributed information retrieval, knowledge-based information access.
1. Introduction
Perhaps the main challenge facing enterprises today is ensuring that mission critical information is made readily and easily available to those in the enterprise who need it. Enterprises have traditionally used a variety of database systems to store and organize data and have struggled with the concomitant issues of disparate, and often conflicting, data models and access mechanisms. In recent years, this problem has been exacerbated by the availability of large numbers of information sources outside of the enterprise that are also important to the operation of the enterprise. A further complicating issue is that end users are also increasingly making use of non-traditional data to support their activities. Images, video and sound are now easy to capture and store in digital form, and potentially offer a wealth of information not readily available in the past.
In our view, information access is not a separate activity that a user performs in isolation from other responsibilities, but rather is an integral part of the overall working environment. As we move towards this new data rich world, we need to develop advanced information access systems that can both deal directly with the heterogeneity and autonomy of the sources in the underlying information space, and give the user the ability to move easily between tools that aid in the execution of specific tasks and those that help locate and analyze information to support these tasks. Thus, given the disparate nature of the emerging information sources, the need to maintain access to legacy sources, the heterogeneity of the software and hardware systems used to host the sources, and the need to provide end-users with transparent access to the massive underlying information space, we need to develop new paradigms for information search and retrieval that can form the basis of these future information systems.
A powerful general model of the software architecture needed for this next generation of information systems was recently proposed by Wiederhold [1] and involves the use of intelligent mediators that support various transformations between end-users and the information sources. In the spirit of this architectural vision, Booz, Allen has developed a prototype system, called MINERVA, that provides knowledge-based, mediated access to heterogeneous information sources.
In this short paper we describe the overall MINERVA system, discuss our approach to providing heterogeneous access to full-text databases, and introduce our current research in extending the MINERVA model to structured data access.
2. The MINERVA System
MINERVA[1] is an open, client-server system that: uses TCP/IP for basic network connectivity; uses an extensible, object-oriented meta-language for application level communications; and, encapsulates information sources (especially legacy information sources) using source specific "wrappers." MINERVA uses two kinds of mediators to support access:
* Query Mediators that first transforms users queries into a series of finer-grained information requests, and then probabilistically combines and evaluates the responses received from the individual sources; and,
* Source Mediators that first transform the fine-grained requests from the Query Mediator into source specific requests, and then transform the responses from the specific sources into a form that the Query Mediator can use for combination and evaluation.
In the remainder of this section, we described the underlying MINERVA infrastructure, outline our approach to Query Mediation, and discuss the nature of Source Mediators for full-text and structured databases.
2.1. The Distributed Information Operating Environment (DIOE)
MINERVA is designed to implement mediated access against information sources that are physically separated from each other and from the user. It is also designed to provide access when the information sources have a native search capability (e.g., a text search engine, or an RDBMS), without removing or bypassing this capability. In this way it can operate in distributed environments and with legacy systems. We call the environment that deals with the distributed nature of the sources and users the Distributed Information Operating Environment (DIOE).
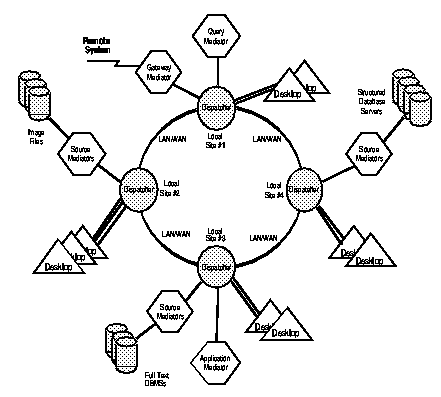
Figure 1 shows an instance of the DIOE that illustrates it's main features and is intended to give some context to the technical discussion in the following sections. As the figure shows, the DIOE has three key functional components:
* Dispatchers that manage the passing of messages (related to queries, results and various administrative functions) among the distributed resources;
* Query Mediators (we only show one in this figure) that perform query decomposition and scoring; and
* Source Mediators that allow information sources to connect into the DIOE.
Although the figure shows four Dispatchers with Desktops and services attached, the ring can contain any number of Dispatchers and the services themselves can exist anywhere in the ring. So, for example the figure could just as easily have shown two Dispatchers with the Desktops attached to one Dispatcher and all the other services attached to the other Dispatcher. The point is that the DIOE is a flexible, configurable environment that allows users, information sources, and other services to be connected in completely unrestricted ways.
Figure 1. The MINERVA DIOE.
The basis of the open architecture is the Dispatcher, which acts as a router for its own local service network. The Dispatcher obtains requests from local users (these originate at the desktops shown in the figure) and decides which local service can handle these requests. In addition, the Dispatcher passes the requests on to other available Dispatchers. Services can be any process that is connected to the Dispatcher -- for example, applications (shown in the figure as an Application Mediator), Query Mediators, any form of Source Mediator (we show connectivity to text DBMSs, structured DBMSs, and images DBMSs), and Gateway Mediators to other systems. Dispatchers connect to one another in a virtual ring, and MINERVA contains capabilities for establishing connections to the ring and for managing the processing in the ring.
2.2. Concept-Based Query Mediators
Query Mediators in MINERVA make use of the concept-based retrieval technology developed by ADS [2]. In this approach, users formulate queries using "concepts" that have meaning in the application domain. Concepts are domain dependent entities which carry the semantics of that domain and which can be described and organized without reference to specific information sources. It is important to realize, however, that the representations of domain knowledge developed using this approach will not, in general, be exhaustive descriptions of that domain, but rather will constitute a Retrieval Model that reflect the information needs of the user (or user group) that developed them. That is, this approach is intended as a way of describing valuable (to the user) distinctions in the domain rather than as an "expert" on specific topics.
To make some of these ideas more concrete, we will use a simple, running example throughout the remainder of the paper. This will allow us connect together the various technical themes of our research effort. Our example focuses on an intelligence analyst who is tasked with monitoring events that might indicate the potential clandestine delivery of military equipment to Iraq. The analyst has at his disposal various information sources, such as message traffic, imagery and on-line technical information about military equipment, which helps him monitor the event. To support this activity, the analyst will want to draw upon a concept knowledge base that describes events of various kinds and which can be used to focus the search for relevant information.
In our approach, defining a concept corresponds to distinguishing a sub-class of some larger class of entities. To illustrate, first let us suppose that we are interested in various kinds of events, then naming trade events as a sub-class implies that we have some way of distinguishing the elements of this smaller class from those in the larger class. In our approach, the mechanism for describing this distinction is to specify the "attributes" of the sub-classes. A simple example of the representation is shown in Figure 2. Here we assume that our overall goal is to model the
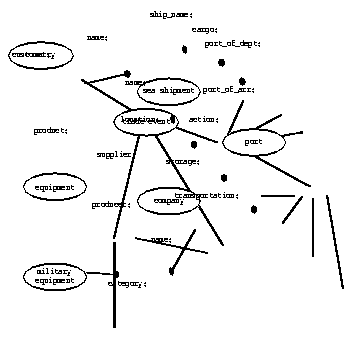
Figure 2. Example Concept Definition.
domain of trade events and that for us a trade event can be defined in terms of actions, customers, suppliers and products. In the figure, trade event is a concept (shown as an oval) and the rest are attributes (shown as labelled arcs between ovals). For the purposes of the example, we further assume that customers are countries, suppliers are companies, products are various kinds of equipment, and that a sea shipment is an action of interest. These concepts in turn can have attributes (as shown). Any given concept can also have sub-concepts, and we show one instance of this in the figure where military equipment is defined as sub-class of equipment (indicated by the solid unlabelled arc).
A simple query corresponding to the concept of a trade event would then be successively decomposed by the Query Mediator into the lower-level domain concepts using the information in the concept knowledge base. When the terminal domain concepts are reached, the decomposition then proceeds by interpreting the "source reference language" expressions attached to these nodes.[2] This decomposition is shown schematically in Figure 3.

Figure 3. Knowledge-Based Mediation in MINERVA.
The figure illustrates the process of decomposing a user query, which may involve multiple concepts, using the network of concept definitions, down to the source reference language components. In general, terminal nodes may have multiple source reference language expressions attached to them, although in the figure, for the sake of clarity, we separate out the text, structured data and image reference components.
The individual source reference expressions are communicated to the Source Mediators, via the DIOE, and converted into native query language expressions that can be applied to the actual sources. The information returned by the individual sources (i.e., information about which data objects satisfied the source reference expressions, together with a numerical measure of the degree to which the expressions was satisfied) is passed back to Query Mediator where the individual pieces of "evidence" are combined to produce an overall measure of the relevance of the data objects to the original request.[3] Once this combination process is complete, the Query Mediator communicates the final results back to the user Desktop from whence it originated.
2.3. Full Text Data Access
The current implementation of MINERVA provides a flexible, scalable approach to heterogeneous text database access. In this section we briefly describe the techniques we use as a way of introducing some of the basic ideas that underpin our solution to the more general problem.
For accessing text databases we have develop a general "Text Reference Language" (TRL) into which concept-based queries are decomposed. The TRL provides a mechanism for defining patterns of text which, if they appear in the body of the document, can be taken as evidence for a concept. To illustrate, suppose we have the following definition of the concept of a SCUD missile in our concept KB:
CONC:+:Scud_Missile
SCOP:PARAGRAPH
PATT:100:100:(OR SCUD SCUD-C)
PATT:90:100:(SENTENCE MISSILE TEL)
PATT:60:100:(OR SSM PHRASE(MOBILE MISSILE))
where the lines that begin PATT: indicate that the expressions that follow are statements in the TRL. The pairs of integers associated with each PATT: line represent the necessary and possible support that the evidence gives for the concept. The SCOP: line that precedes the PATT: line, define the "scope" within which evidence for the concept is to be gathered. Here it has value PARAGRAPH, indicating that the focus of the evidence gathering should be at the paragraph level, so that a document that has all three pattern expressions satisfied within the same paragraph will generate a higher score than a document that contains them spread throughout the document. The TRL expressions themselves are to be interpreted in an obvious way and are directly analogous to the keyword-based query languages usually found in commercial text retrieval systems (e.g., BRS/Search, NEXIS, DIALOG). The key distinction, however, is that the MINERVA TRL is not specific to any particular retrieval system and is designed to be a more general query language.
The advantage of this strategy is that we can then develop intelligent Source Mediators that transform the MINERVA TRL requests into native query language requests. Not all text DBMS support all the operators defined by the TRL, so part of the knowledge contained in the Source Mediator is the definition of these translations. So, for example, many DBMSs do not support the SENTENCE operator and in such cases the Source Mediator might replace this with a conjunction. Similarly, some DBMSs might not support the PHRASE operator and the Source Mediator might replace it with some form of adjacency operator. The net effect is that the Source Mediators provide a "fill in" capability that allows each individual text source to behave like a fully functional TRL source. This needs to be contrasted with some other approaches to heterogenous text database access in which the common query language is the "lowest common denominator" of the individual source query languages. This is illustrated in Figure 4.
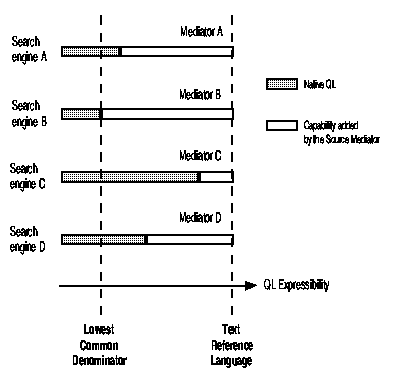
Figure 4. Full-text Database Encapsulation.
2.4. Structured Data Access
While many enterprises make extensive use of structured data,[4] they also often use a variety of database systems to store and organize the data, and have then to deal with the issues of disparate, and often conflicting, data models and access mechanisms. This is widely studied problem and a great deal of literature has appeared in recent years. Within the MINERVA framework proposed here, the challenge is to exploit this body of research to design and develop Query Mediators that can treat text and structured data in a uniform and transparent manner.
The MINERVA approach is to exploit the existing knowledge-based Query Mediator by extending the concept knowledge-base to incorporate (concept-based) models of the structured databases, and by extending the source reference language so that it can define evidential primitives both for text and structured data. The advantage of this approach is that, from the user's perspective, all information requests use the same query language and are always described in terms of domain concepts, even though the underlying data models are quite different.
The key difference between the structured database access problem and the text database access problem is that we have to consider the issue of representing the semantics of each database instance. That is, it is not sufficient to provide a generic Source Mediator for a particular DBMS, as we can do with text, but rather we actually have to model the data stored in the database if we are to access it intelligently. Thus if we are to connect to structured databases as well as text databases, somewhere in the information system there has to be a semantic model of this structured data.
The primary research issues we are addressing in this approach are:
* the development of tools and techniques for building the concept-based model of the structured data;
* the development of tools and techniques for merging the concept-based model derived from the structured data with an existing concept KB;
* extensions to the knowledge representation to include a more general "Source Reference Language" that subsumes the existing TRL and also provides a mechanism for incorporating "SQL-like" expressions;
* modifications to the Query Mediator to exploit this extended knowledge representation; and
* extensions to our model of what a retrieved object is so that the results from text and structured databases can be "fused" in a coherent way.
Our results to date are very preliminary, but to help illustrate the ideas we are pursuing in addressing these research challenges, Figure 5 shows what a model of a simple database might look like using an object-oriented representation. The upper left part of the figure shows the schema for a a part of a database that deals with international trade events, and the lower right shows what an object-oriented model of it might look like (we use the same notation as in Figure2). Obviously, there are a number of difficult problems that need to be addressed in building this model and we are currently making use of ideas develop by various groups (e.g., the Carnot Project at MCC [3] and the Pegasus Project at Hewlett-Packard [4]) to develop tools that help partially automate this process.

Figure 5. Object-Oriented Model of Relational Schema.
The next step in our proposed approach is to "merge" the model shown in Figure 5 with the one shown in Figure 2. Again there are some significant challenges in attempting to do this automatically and for now we are pursing machine-aided approaches, rather than fully automatic ones.
The main focus of our current activity is on the definition of a general purpose Source Reference Language (SRL) and on the necessary changes we have to make to the knowledge representation and to the inference mechanisms used by the Query Mediator. We are exploring a structured SRL that uses ideas from SFQL and object-oriented extensions to SQL, and are looking at a number of inference strategies, including a single unified reasoning model that treats text and structured data records as sub-classes of a more general retrieved data object. This unified approach also allows us to begin addressing the problem of merging search results when they come from heterogeneous sources.
3. Summary
The MINERVA system described in this short paper is a prototype of the next generation of information systems that will be needed to take advantage of the evolving National Information Infrastructure. Applications such as Digital Libraries are a natural use of the MINERVA technology.
Acknowledgments
We would like to acknowledge the rest of the MINERVA team: Steve Ciccarelli, Steve Crutchfield, Dave Pool, Steve Sandke, Chris Smith, Bill Terry, and Lee Appelbaum.
References
[1] G. Wiederhold. "Mediators in the Architecture of Future Information Systems." Computer, 25(3):38-49, March 1992.
[2] R. M. Tong, L. A. Appelbaum, V. N. Askman. "A Knowledge Representation for Conceptual Information Retrieval." International Journal of Intelligent Systems, 4(3):259-283, 1989.
[3] C. Collet, M. N. Huns, W-M. Shen. "Resource Integration Using a Large Knowledge Base in Carnot." Computer, 24(12):55-62, December 1991.
[4] R. Ahmed, P. De Smedt, W. Du, W. Kent, M. A. Ketabchi, W. A. Litwin, A. Rafii, M-C. Shan. "The Pegasus Heterogeneous Multidatabase System." Computer, 24(12):19-27, December 1991.
[1] The MINERVA system is the result of an internally funded Booz*Allen project that to date represents approximately 12 person-years of investment. MINERVA currently provides a general purpose full-text database access capability, and is being evaluated by several users within the DoD, where it is being used to access a number of commercially available full-text systems including Verity Inc.'s Topicreg., BRS' BRS/Searchreg., Open Text's PAT, and both the public domain and WAIS Inc. versions of WAIS.
[2] Source reference languages are the mechanism we use for specifying the lowest-level information requests in the MINERVA meta-language.
[3] In our model, the basic statement of belief is a qualifier that attaches to a concept. Statements of belief are then statements about the degree to which the evidence we have supports or denies that the data object is relevant to the query concept. We make the further assumption that support for a concept denies its negation, but we do not rule out the case in which the evidence leaves us partially ignorant (as opposed to uncertain) about the query concept. That is, we allow for the situation in which the evidence tells us nothing about the concept. This results in an interval-based evidential calculus in which we manipulate both the necessary and possible degrees of support for concepts.
[4] By structured data we mean, of course, data that is
stored in a traditional DBMS, such as Sybase, IMS or IDMS, and which can be
represented using one of the standard data models -- that is, the relational,
hierarchical or network data models.
Last Modified: