[1] School of Information Studies, Syracuse University, liddy@mailbox.syr.edu, mike@ericir.syr.edu, cmcclure@suvm.syr.edu,
[2] Northeast Parallel Architecture Center, Syracuse University, kim@npac.syr.edu,
[3] Scholastic Press, Inc., New York City, New York, susanim@aol.com,
[4] NYSERNet, Liverpool, New York, luckett@nysernet.org
Keywords: Intelligent information retrieval, natural language processing, HPCC, K-12 education, information policy, user studies.
Goals & Objectives
The Intelligent Digital Library Project has two primary goals:
1. Intelligent Retrieval: To accomplish a level of non-mediated intelligent retrieval in a networked environment that is now possible only with the assistance of a human intermediary.
Based on the ARPA-funded DR-LINK natural language processing (NLP) approach to representation and retrieval, we will create and test a Digital Librarian to simulate the human intermediary's ability to retrieve information on the basis of what people mean in their query, not just what they say. Documents will be "understood" in the same way--their content represented at the conceptual level of expression. DR-LINK is a prototype system that has been extensively tested on hundreds of queries and gigabytes of documents. Porting the system to a new user-base, broader ranges of document types, and a distributed environment will entail basic NLP and information retrieval research. The performance of the Digital Librarian will be tested in relation to the human intermediary and current retrieval systems. Our objectives associated with this goal are to investigate:
2. Development, Impact, and Policy Issues: To investigate the development, impact, and policy issues associated with creating the first significant digital library collection of learning materials for
K-12 educators and students.
The testbed will include a rich and useful collection of primary materials in math and science, a significant collection of teacher education materials, and extensive resources focusing on key issues and aspects of teaching, learning, and management. It will also contain a broad array of newspapers, journals, and video clips. Specific objectives are to investigate:
The Research Team
Leading the project is a research team drawn from academic units, research centers, and commercial information providers:
Joining this team are contributing partners from a wide range of commercial and educational institutions. They will be integrally involved with creating the digital library, conducting formal user research, developing software, making network connections, and investigating policy and impact concerns. These partners include:
Project Organization
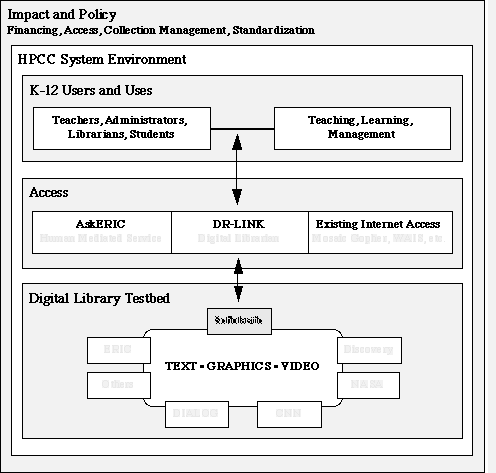
To achieve the project goals, our research and development efforts are organized into five major components. Figure 1 shows a unified model of the project, integrating the various components.
(1) Users and Uses: K-12 teachers, students, librarians, and administrators will seek out resources in the digital library for:
The formal test groups will include the full range of "real users," ranging from those at sites with low-end platforms and access (e.g., VT100 at 2400 bits per second) to those with high-end platforms and access (e.g., graphics clients at T1 and beyond). AskERIC and NYSERNet will coordinate the user groups in terms of training, support, and sampling for the various research studies. NPAC, with assistance from NYSERNet, will coordinate access.
(2) Digital Library Testbed and Facility: The testbed will integrate text, bibliographic, image, and video resources from a number of partners. Scholastic, Inc. will coordinate, with assistance from AskERIC, the development of the digital library testbed. NPAC will provide the host environment and networking facilities for the testbed.
(3) Intelligent Retrieval: Users will be able to access the digital library through an intelligent Digital Librarian that the research team will develop, in addition to accessing it through existing Internet retrieval methods and the AskERIC human intermediary service. This will enable direct empirical comparisons between the intelligent Digital Librarian and the existing human-mediated computer-based systems. The Digital Librarian will also be extended into a more adaptive, connectionist NLP system. IST will coordinate the research, development, and testing with assistance from NPAC and Xerox PARC, and image retrieval with Scholastic, Inc. and Dialog.
(4) HPCC System Environment: The technological foundation for the testbed, retrieval systems, and interactions with users will be the HPCC environment. NPAC, working with IST and Scholastic, Inc., will integrate an evolving high-performance retrieval system with a range of delivery modes. Research on scalable NLP systems with distributed, multimedia databases will provide needed insight into digital library performance issues.
(5) Impact and Policy: Underlying all of these components as well as the ultimate success of digital libraries is the need to determine the impact on performance and behavior and to understand the issues related to financing, access, collection management, and standardization. IST will coordinate the impact and policy studies with assistance from Scholastic, Inc. and AskERIC. A number of partners will also participate in conducting assessments and forming recommendations.
Figure 1. The Intelligent Digital Library Model.
Research Plan
The proposed research covers a wide spectrum of disciplines and addresses a rich set of issues that need to be answered in order to provide the maximum in digital library services--from constructing the testbed, to networking a large number of sites, to developing an HPCC implementation, to conducting basic research in information retrieval, to evaluating the digital library's impact on its users' everyday lives, to the policy issues that surround this rich new service. The basic research we will conduct in this project will cover the following major areas:
(1) Intelligent retrieval via a natural language text retrieval system (DR-LINK)
(2) Scale-up of intelligent retrieval in an HPCC environment
(3) Evaluation of digital libraries' impact on users' behavior and performance
(4) Policy implications of the creation, use, and availability of a digital library
Together, the outcomes from these major research efforts will provide the means for moving toward the digital library of the future that is effective, efficient, and widely beneficial.
Research Area 1: Intelligent Retrieval
Problem: Information seekers want to express their information needs naturally and with all necessary detail. They want the system to understand the underlying meaning of their query in all its complexity and subtlety. Equally important, they want the system to have represented the contents of documents at a sufficiently rich level that it can respond to their query at its deep, conceptual level. Instead, information seekers currently find that network access does not provide for substantive, complex queries expressed in a full, natural mode of expression to be responded to sufficiently. Most searching and retrieval via the networks is currently performed at the surface string-matching level--word for word matching with no accounting for the complexity and ambiguity of the language. Furthermore, users cannot find the information they need in an easy, straightforward manner that would encourage their continued use of the network as an information resource. Although some information seekers overcome the hurdles in their path, the available network tools do not encourage access, nor do the circuitous routes whereby one may find the gem lodes (given persistence, good luck, and sufficient time) invite extensive usage.
Solution: To overcome these barriers, we are proposing to develop a Digital Librarian that can understand and act upon the same type of wide-ranging natural language queries that users so easily and naturally ask of a human intermediary. The documents, as well as the text accompanying images, in the digital library testbed will be processed into a linguistic representation as rich as that of the queries so that truly conceptual-level retrieval can be performed.
The testbed's intelligent retrieval capability will come from DR-LINK, a prototype text-retrieval system developed under the auspices of ARPA's recent TIPSTER Initiative (Liddy & Myaeng, 1993). DR-LINK (Document Retrieval Using LINguistic Knowledge) was developed to serve the information needs of analysts who have complex, high-precision/high-recall information needs, which are input in unrestricted natural language. Although the average network inquirer may not currently be in the practice of posing queries as detailed as the analysts', research has shown that users will easily produce rich, complex statements of their information needs if they know that the system can use this level of specific relevance requirement for more productive results (Oddy et al., 1992).
The NLP approach implemented in DR-LINK represents and matches documents and queries at all levels of linguistic expression (morphological, lexical, syntactic, semantic, and discourse) at which meaning is conveyed for purposeful communication by human beings. In concert, these levels of representation provide the capabilities whereby the system can truly aspire to intelligent retrieval. Given this full range of linguistic processing, DR-LINK has the potential for providing a level of intelligent retrieval that is now available only through a human intermediary. That is, DR-LINK will:
* comprehend the subtlety of a user's information need;
* recognize the user's multiple dimensions of relevance requirements;
* understand the complexity of ways in which relevant information might be expressed in various information sources; and
* retrieve those documents that are responsive to a query at the conceptual level.
Research Topics: We will investigate three basic research topics within the project's intelligent retrieval component. The three basic research goals are:
A. To develop an intelligent retrieval system that will use NLP to respond to information queries with performance comparable to the information provision capabilities of human intermediaries.
This basic research will involve the development of the Digital Librarian which will emulate the information skills of the human intermediary whose understanding of both theuser's information need and the information content of documents is not limited to surface-level lexical comprehension; rather, the intermediary interprets queries and documents at the multiple levels at which meaning is conveyed in human language, from pure lexical pattern matching, to recognition of all semantic equivalencies of needed concepts, to the discourse level where structuring of information content conveys important aspects of a text's meaning. We propose to bring this same level of natural expression and system understanding to the broad range of users who will access the digital library.
Within this project, we will create a Digital Librarian that simulates the human intermediary's ability to retrieve information on the basis of what queries and text mean, not just what they say. This will be done by extending DR-LINK's successful but still nascent NLP approach to the representation of the queries that will be put to the digital library and to the processing of the library's contents into the enriched linguistic representation provided by the DR-LINK system.
B. To achieve a major paradigm shift from the symbolic NLP approach used for processing documents in the current DR-LINK Information retrieval system to a more adaptive, robust, connectionist NLP approach.
The NLP approach we have pursued in DR-LINK is symbolic in nature. Successful and impressive at
the conceptual level, it relies on intensive domain knowledge and a rule base. However, the need to extend its use to new types of texts and queries has caused us to re-evaluate the basic paradigm. Although the system is not domain-dependent, its symbolic NLP approach requires much human effort in the discovery and coding of the necessary regularities (rules) in text and the development of linguistic knowledge bases. Applying DR-LINK to a new environment therefore might be more time consuming than is necessary, undermining the versatility and practicality of our system. To significantly reduce this overhead of human effort, the DR-LINK system needs to be transformed into an adaptive system that, when applied to a new environment, can automatically extract (or learn) the rules (or regularities) and encode the knowledge. The connectionist (neural network) approach possesses several important properties that can be exploited to build the adaptive version of the DR-LINK system.
In building an adaptive version of the DR-LINK system that can learn the statistical regularities and rules, we will use two types of neural networks, the feedforward neural networks with the backpropagation algorithm (Rumelhart et al., 1986) and the simple recurrent networks (Elman, 1990; 1991). The former possesses all the desirable properties described in the previous paragraph and will be used to learn the required and, possibly, non-linear, I/O mapping in the DR-LINK system (e.g., the mapping between the lexical clues and the text structure components). The simple recurrent network is an extension of the BPFFNNs and is capable of learning and recording temporal information. This additional property is extremely useful for an NLP system such as DR-LINK, because it enables us to build a connectionist NLP model that retains many properties of conventional symbolic models, such as context sensitivity and sensitivity to the compositional structures (Sharkey & Reilly, 1992). In the process of constructing such an adaptive system, some related issues also need to be investigated. They include the determination of the appropriate network size and topology, the proper construction of the training set (samples) that reflect the essential characteristics of a domain, and the evaluation of the new system's performance in comparison with the symbolic version of the DR-LINK system.
C. To understand the information-seeking behavior of image seekers in order to extend the Digital Librarian's capabilities to include the intelligent retrieval of images, first via the natural language annotations that accompany the images in our testbed, and eventually via retrieval on the features of images themselves.
In the area of image retrieval, there will be two levels of effort. From the first day that the testbed is accessible, we will be able to provide images as well as text as an information source by using the text that accompanies the majority of images in our testbed (e.g., captions on photographs or lesson plans accompanying CNN footage). DR-LINK will process the accompanying text, enabling us to provide text-based image retrieval by means of the NLP retrieval capabilities available in the system.
As the project advances, image retrieval will move to a second level of investigation--a basic inquiry into preferred methods of searching for images. We will conduct an exploratory, observational study of users searching for images. To understand which aspects of images (both fixed and moving) are important for searching, and what mechanisms are needed for both indexing and retrieving images, we propose to investigate the types of searches real users engage in when looking for a particular image, and which aspects of the images are important for successfully retrieving it. We will observe the testbed's users to learn how they search collections and what aspects are important for retrieval.We are interested in learning:
* What aspects of images are important for searching?
* What types of searches do users engage in when looking for an image?
We will first incorporate what we learn from these observations into the DR-LINK query sublanguage analyzer. Then will empirically test text-based vs. icon-based searching for images, as well as the use of DR-LINK's natural language query analyzer to map users' free-text queries into a controlled vocabulary searching thesaurus.
Research Area 2: High-Performance Digital Library System
Overview: The electronic digital library will inevitably be distributed over the Internet; this does not present a barrier to meeting the needs of users, because it is easier to move from one network location to another than to walk into an adjoining room in a physical library.
Each digital library site of the future must be capable of storing massive amounts of text and image resources and of providing both local and remote users with intelligent retrieval methods. These requirements dictate the need for an HPCC environment.
At each site, there will be overhead and potential bottlenecks associated with the activities of (a) locating documents, which can be computationally intensive, and (b) retrieving and delivering documents, which relies for speed on file retrieval hardware and software, on network bandwidth, and on communication protocols. A cost-effective and efficient site will support these activities in a system-balanced manner, such that, for example, the available bandwidth is matched to the speed with which documents can be retrieved and these are matched to the rate at which requests can be processed by the computational engine.
Achieving a balanced system requires monitoring all aspects for bottlenecks and often implies using data so acquired to reconfigure the system. Research, prototyping, evaluation, and feedback cycles will be important for all aspects of system and network performance. An intelligently modular design is also important so that changes can be made with little impact on system stability.
Problem: The digital library of the future must be capable of storing massive amounts of text and image resources and of providing both local and remote users with intelligent retrieval methods. These requirements dictate the need for an HPCC environment. To adequately meet the demands of an effective digital library, it will be necessary to create a balanced system that will efficiently handle very large digital libraries of text and multimedia, that is responsive to the need for different types of searches and different requirements for organizing information, and that is distributed and modularized in such a way that it will maintain its integrity and performance as it is (a) indefinitely expanded and (b) upgraded at the hardware and software component level.
Solution: To meet this need, we propose to create a fully distributed client/server document retrieval system operable across platforms and at any bandwidth. Specifically, we plan to:
* Develop parallel versions of DR-LINK and document retrieval
* Develop multiple types of servers for handling the various retrieval and application functionalities
* Develop effective message-passing that has good performance for both small messages and large data transfers and can convey all necessary information among modules
* Separate document storage management from information management
* Work closely with users to effect a user access design that reflects the ways users work naturally or intuitively with the system
Research Topics: The HPCC component of the research centers on three fundamental research goals. These are:
A. To enhance scalability by networking the DR-LINK environment and developing a high-performance version of DR-LINK document processing.
B. To integrate DR-LINK with other types of electronic information, such as multimedia and relational databases.
C. To scale the digital library testbed environment so that it can adequately handle the massive amounts of diversified traffic it will be called upon to support.
These goals raise a number of issues that we will need to address. These include:
* Transaction management for DR-LINK natural language query processing
* Parallel processing strategies for optimizing text processing
* Balancing I/O with the central processing unit (CPU) processing both for creating the text database index and for handling multiple complex queries
* Design of client interfaces, incorporating user-driven options
* Refinement of the design by evaluating user interactions with the system
* Continuing research on the use of computer processes and procedures as sources of real information in virtual documents (i.e., information creation by simulation, data analysis, database mining)
* Integration of text search with heterogeneous data types and with complementary search methodologies, such as image pattern recognition and standard query language (SQL) queries
* Efficient delivery systems that are performance-balanced from file storage to display
Supporting research will include strategies for facilitating fast multimedia file retrieval, developing and optimizing network transfer protocols, evaluating network traffic, and evaluating the total HPCC query processing and documents delivery system for bottlenecks as the basis for design refinement.
Research Area 3: Impact of Digital Libraries
Problem: Past introductions of new information technologies and systems suggest there will be both intended and unintended users, uses, and barriers to the use of digital libraries. And although there has been much fanfare in the media about the significance of the new "information highway," little is known empirically about this new technology's effect on the behavior, practices, and outcomes of individuals and organizations.
Solution: Given the almost immediate availability of our digital library testbed to the K-12 environment, we will be in the fortunate position of being prepared to conduct longitudinal evaluation studies of its impact over the span of the project and perhaps beyond.
We will identify and collect data about specific services or activities, establishing criteria by which their success can be assessed, and determine both the quality of the service or activity and the degree to which the service or activity accomplishes stated goals and objectives (Van House, Weil, and McClure, 1990). As such, our evaluation will (1) insure that the highest-quality services are provided to the intended users of those services, and (2) assist decision makers in allocating necessary resources to those activities and services that best facilitate the accomplishment of organizational goals and objectives (Hernon and McClure, 1990).
Research Topics: This project will provide the educational community with network access to the first K-12 digital library. For this model to be used for more extensive application, we must know what impact the project has on its targeted user groups. Our evaluation studies will be guided by the following research topics:
A. What is the degree to which digital library services and materials resolve user information needs?
Ongoing monitoring and evaluation of how users assess the quality of digital library service, and for what purposes digital information is being used (as compared to traditional types of information), can help the testbed's designers to better respond to the needs of users and potential users.
B. What are the costs for developing the digital library as a whole, as well as for specific individual services?
Planners of digital libraries need information as to what costs can be expected in the development of digital library products and services. However, the traditional cost categories that are used in planning conventional libraries may not be appropriate for use in a digital library context. Being able to conduct cost analyses of selected services is essential for conducting the policy research on pricing services.
C. What are appropriate performance measures for assessing the efficiency, effectiveness, extensiveness, and impact of digital libraries?
In addition to determining the degree to which digital libraries resolve user information needs and identifying digital library costs, it is essential to extend research on developing performance measures for digital libraries. Work by Van House, Weil, and McClure (1990) has demonstrated the importance of developing validated performance measures for academic libraries. This research will be extended into the digital library environment.
The research questions identified here are significant and suggest that ongoing user-based evaluation of the digital library's impacts should accompany the design and implementation of specific services. These key questions will help the research team to better understand the impact of digital libraries and provide ongoing, user-based, formative assessments that will inform decisions related to the design and management of this and future digital libraries.
Research Area 4: Policy Research on Digital Libraries
Problem: The networked information environment, so far, has been driven primarily by the technology of computers, electronic networks, and telecommunications facilities. Government and the larger society are now witnessing the preliminary results of a technology-driven approach to the information infrastructure. These results include disparities between those who can and those who can't access networked resources; conflicts over privacy and access to information; reluctance on the part of information creators to make their information available because of cost/pricing concerns, and intellectual property protection; the competing, sometimes conflicting use or the complete lack of technical standards; and other societal and political issues and concerns.
Solution: Our research includes a specific component to investigate policy issues related to the creation, use, availability, and effectiveness of a network-based multimedia digital library. The effort will draw upon, in part, the digital information developed for inclusion in the digital library as well as policy analysis of these topics from broader perspectives , e.g., the existing Federal laws and regulations. After identifying existing policy in the areas addressed by the research questions detailed below and the issues guided by those questions, we will develop and assess policy options and recommendations in the areas of:
* Financing and pricing information resources and services in a networked environment
* Providing universal access to and universal usability of digital libraries
* Managing the information resources contained within a digital library and addressing such critical concerns as intellectual property, privacy, and censorship
* Developing and implementing technical standards and standardization policy for digital libraries
Policy research and analysis in these key areas will provide the foundation for counteracting the current technology-driven nature of the emerging information infrastructure. In this way, the research will assist policy makers, users, and other stakeholders in resolving the more complicated social, political, and economic questions that have emerged with the development of the networked information environment.
Research Topics: The following research questions address critical concerns for digital library and networked information environment operations and use.
A. What collection and access management policies can effectively address the characteristics of networked information services and resources?
Traditional, print-based libraries have developed policies to manage their collections and access to them. The networked environment calls into question these traditional notions of collection development as well as the patterns of access and use of information resources. It also calls into question long-standing intellectual property arrangements among publishers, information providers, libraries, andtheir users. Publishers and electronic information providers are currently experimenting with various models to assure copyright protections and other intellectual property rights in the electronic environment. Collection development by digital libraries must accommodate information providers' concerns regarding these rights.
Traditional libraries also have developed effective safeguards on patron privacy, and many libraries have in place statements and policies on intellectual freedom and censorship. Digital libraries will need similar policies, modified to reflect the specific characteristics of the networked environment. This research will identify policy categories related to collection and access management and detail the priority issues in each category. Our goal is to develop and recommend a policy framework for this broad area of collection and access management.
B. How will digital libraries be financed, and how will information resources and services be priced, in a networked environment?
Networked services and resources are not free, although for many users they appear to be "free" because there are no direct charges attached. The operation of a digital library will require funding, and it is still unclear (1) how digital libraries will be supported, and (2) how they will cost and price their services.
Pricing is a key policy issue that has yet to be addressed and resolved for the delivery of any networked information service, resource, or product. Indeed, it is impossible to address pricing policy without considering other policy issues, such as the public and private sectors' roles in financing digital libraries and access to them. There exists a well-established body of literature related to the economics of information, but there is less knowledge about the economics of digital information, especially digital information within the context of a digital library.
This research question will guide an investigation into the costs of digital libraries (e.g., network connections, digitization of information, distribution, etc.); their pricing of resources, products, and services; and funding mechanisms to support digital libraries. Models for these three areas will be developed that can inform policy options and recommendations.
C. What constitutes universal access to digital libraries, and who is responsible for ensuring that such universal access occurs?
The Clinton Administration's National Information Infrastructure: Agenda for Action (1993) identifies "universal access" and "universal service" as key operating principles for the evolving networked information environment. These terms have yet to be operationalized, and, equally important, some critics have questioned the purposes to which universal access will be put. There appears to be a close connection between the policy of universal access and the resulting utility and effectiveness of that access.
Barriers that impede universal access to networked information need to be identified and policy must be developed to minimize the impact of those barriers. Some of these barriers are related to the notion of technical and network literacy, the collection of technical or other skills users will require to use digital libraries effectively.
D. What technical standards are needed for the components of the digital library, and what are the mechanisms for evolving these standards?
Technical standards are embedded within the technology that currently is driving the networked environment. The range of standards that may be useful for digital libraries is extensive and includes standards for telecommunications and computer protocols, data formats, and data interchange, among others. Unfortunately, conflicting and competing standards and standards development processes and organizations may reduce the likelihood of seamless interoperability and interworking of the components of the networked environment. In addition, the dynamic nature of existing and emerging information technology calls into question whether the traditional standards development processes can respond in a timely manner with useful (i.e. implementable) standards.
Policy research is needed to identify which standards will be necessary for an effective interoperable and user-based digital library. An inventory of existing and proposed standards will assist in determining the degree to which they meet or conflict with emerging operating requirements for a digital library.
Research is also necessary to determine the mix of responsibilities among the government, public, and private sectors in the development of standards. Since there is no existing or overarching standards policy that guides the development of standards for the information infrastructure, this research will identify the components and responsibilities for a model of standards development that responds to the needs of digital libraries.
Significance
This research directly addresses the key concerns of emerging digital libraries. Owing to the range of expertise of the research team, we are well prepared and capable of investigating the following topics. In particular, we will:
Categorize/index/organize electronic information:
* Integrate public and commercial text, still-image, and video collections in one testbed. Most of the collection has already been digitized, thereby permitting us to focus on the content and access issues from day one of the project
* Produce a level of conceptual indexing quite beyond the capabilities of normal keyword indexing techniques by using the multiple levels of linguistic processing produced by DR-LINK
* Provide subject classification of, and seamless subject access to, documents stored in distributed databases via the proven Subject Coding approach of DR-LINK
Develop advanced software for searching/filtering/browsing:
* Extend the discourse-level processing by DR-LINK to new genres and query types for improved intelligent retrieval
* Achieve and empirically compare with human retrieval performance, a new level of intelligent retrieval via NLP of both texts and queries
* Improve DR-LINK's robustness and portability by developing an adaptive, connectionist model of the current symbolic NLP system
* Develop a data-grounded understanding of users needs and search behaviors in image retrieval and produce a model for feature-based indexing
* Empirically compare text-based and icon-based indexing and retrieval of images
Address networking standards/protocols/policies:
* Investigate protocol design as well as scalability issues in an HPCC system implementation
* Conduct users based studies to learn the impact of the digital library on its users' behavior and performance
* Develop and validate new performance measures for use in evaluating digital libraries
* Provide recommendations from broad-based policy studies on costs, ownership, financing, access, and other crucial issues
The strengths of the research project include the breadth and significance of the research issues, the coordinated approach, and the extensive expertise of the research team members. In addition, the project incorporates a number of perspectives - academic, public-sector, and commercial - into a unified approach. Additionally, the project's research findings will be directly applicable and transferable to a wide range of business, government, and recreational uses and settings. Lastly, we will produce a digital library and Digital Librarian that will be made available to all educators and students.
Last Modified: