Robert P. Futrelle and Xiaolan Zhang
Biological Knowledge Laboratory and Scientific Database Project, College of Computer Science, 161 Cullinane Hall, Northeastern University, Boston, MA 02115, {futrelle, xzhang}@ccs.neu.edu
Abstract
To build high-quality Digital Libraries, a great deal of up-front analysis needs to be done to organize the collection. We discuss methods for discovering the structure of documents by first analyzing the nature of the language used in the documents. "Bootstrap" techniques are described which can discover syntactic and semantic word classes as well as the higher-order structure of natural language using nothing but the corpus itself. Classical character-based methods of corpus linguistics are incapable of dealing efficiently with the masses of complex data involved in these analyses. We introduce multidatabase methods for handling corpora as word-object-based data. We demonstrate results of word classification applied to a 4 million word corpus from the Journal of Bacteriology. Object-oriented database technology is stressed because of its powerful representation capabilities. However, performance can be compromised in such systems, so we discuss "first-fast" and "successive deepening" approaches to assure good interactive response.
Keywords: Information systems, corpus linguistics, word classification, object-oriented database.
1. Introduction
A high-quality Digital Library should have a fully organized and indexed collection of information. The paradox of the Digital Library, for the serious user, is that the more information there is on-line, the greater the chance that crucial information will go undiscovered. This can happen either through a failure of recall (a Type I error in which the items are not found) or through a failure of precision (a Type II error in which such a large number of items are found that the user cannot look through them all to find the relevant ones) [Salton 1989] . There are many such "serious" users, ranging from neurosurgeons to citizens actions groups, all of whom can afford nothing less than complete and precise information.
To build a DL for a serious user, a good deal of effort must be spent analyzing and organizing the information in advance. But the amount of material coming on-line is so large that it is impossible to manually analyze and organize it in a consistent way. The most recent information is often the most important, but again there is a problem, because whoever or whatever is doing the organization may not be able to deal with new terminology or the extensions needed to organize the new concepts in a timely way.
This paper explores automated methods for discovering the contents and structure of text. The application domain is the biological research literature and the technique is a new one, fusing multidatabase methods [Kim 1993] with corpus linguistics [Church and Mercer 1993] [Zernik 1991] . Multidatabases incorporate aspects of Object-Oriented databases, relational databases and specialized file structures. The challenges of structured text analysis and retrieval are so great that only a heterogeneous collection of techniques can hope to succeed.
The examples discussed here are drawn from analyses of the full text of the Journal of Bacteriology (1993). This corpus totals 4 million words and contains 220,000 distinct words. This represents about 1/10,000 of the annual volume of the world's biological literature which comprises 600,000 articles containing about 3x10 [9] words.
2. Start-up and the steady-state
For automated analysis of text, the system must possess a basic vocabulary and knowledge of the structure of English. It is not necessary to build this knowledge, or even the majority of it, by hand. A large training corpus (many millions of words in a focused domain) contains enough information so that the system should be able to induce the structure and relation of all the important elements of English using extensions of the current methods of corpus linguistics. This initial process of discovery constitutes the start- up phase. We would be the last to suggest that there is anything easy about this problem, but the results obtainable by corpus linguistics methods grow more impressive every year and are worth pursuing vigorously.
Once the training corpus is analyzed and the various patterns of English have been induced, they can be used to analyze the stream of new text entering the system. This is the steady-state regime. New items and structures will continue to appear in the steady-state, but at a greatly reduced frequency.
Here are some of the types of information about language that need to be discovered in the start- up phase:
* disambiguation of words and phrases
* characterization of domain-specific word use
* building domain-specific thesauri for query expansion
* translation of specialized markup (subscripts and superscripts in chemical nomenclature and numerical forms)
* extraction of ontological relations for knowledge frame building
During the steady-state, further information is extracted:
* analysis of internal contents (information distribution among sections and paragraphs)
* document clustering based on domain-specific information
* extraction of the specific contents of documents as knowledge frame instances
3. Databases versus "classical" corpus methods
The power of databases needs to be brought to bear on this problem because the analysis produces complex results that are very difficult to use unless they are indexed and efficiently accessible. In the past, corpus methods have relied very much on character-based representations. Much of the work has been done using linear search methods (grep, Lex) on character streams with processing through Unix pipes and output in the form of ever more complex character streams [Baeza-Yates 1992, Church and Mercer 1993] . Other approaches have used character-based indexing rather than streams, e.g., a permuted dictionary method (rotated strings) [Zobel, et al. 1993] or PAT structures (based on Patricia trees) [Gonnet, et al. 1992] . None of these are databases in the proper sense, since they are all focus on indexing text whose underlying structure is a character stream.. An extensive review of text "databases" [Loeffen 1994] is in fact quite character-based and discusses little in the way of databases per se. An example of a complex character-stream representation (non database) is [Jacobs and Rau 1993] :
[IT///pn] [PLANS/PLAN/S/va] [TO///pp CONSIDERABLY/CONSIDER/ABLE-LY/ad INCREASE///va] [THE///dt STRENGTH///nn] [OF///pp AMERICAN/AMERICA/AN/ad MILITARY///ad PERSONNEL///nn] [UNDER///pp THE///dt FLAG///nn] [OF///pp THE///dt MULTINATIONAL/NATION/MULTI-AL/ad FORCES/FORCE/S/nn] AND///cc [TO///pp EXPAND///va] [THE///dt ZONE///nn] [OF///pp OCCUPATION/OCCUPY/ION/nn] *PERIOD*///86
The character-based methods have another problem, in that they are not well-matched to the structure of natural language. Words are made up not of characters but of morphemes, units that form the building blocks of words and which are attached to one another in various ways. Thus "trees" consists of the base morpheme "tree" and the plural morpheme. One of the problems of the character-based methods is that they go to great lengths to make it possible to do rapid searches for patterns such as "c.t" where "." is a wild card representing any single character. In English, this would return the items, "cat", "cot" and "cut" which do not form any natural set of interest. Wild cards fail in this example by returning too much and in other cases by returning too little (no simple variant of "mouse" returns "mice" nor does "is" return "are").
Pattern-based searches with regular expressions are typically used for run-time analysis of variant word forms, so that "develop*" retrieves "develop", "developed", etc. Since the number of variants of typical English words is small, there is no need to do repeated searches for variants at run time. Instead, all the words in a corpus can be analyzed fully and carefully, off-line and in advance to discover their nature according to the rules of English morphology, augmented by special cases [Ritchie, et al. 1992, Sproat 1992] . A good morphological analysis will "carve words at their joints". It will know, for example, that "discovered" and "led" are past participles but "red" is not. Once this is done, the results are placed in a lexical database. An index can be built which maps every word form to its occurrence positions in the text. Searching as such is no longer needed because all of the occurrences of any item can simply be looked up in the index.
4. "Bootstrapped" word classification
One of the most important tasks in text analysis is to determine the nature of the individual words in the text. Even different occurrences of the same surface form (homographs) may need to be distinguished. e.g., "basic" can describe a solution with a high pH value or something that is fundamental. Natural language parsing needs, at a minimum, the part-of-speech of each word, e.g., whether an occurrence of "number" is a noun or a verb. Part-of-speech taggers have been developed which are quite good [Kupiec 1989, Zernik 1991, Brill 1992, Brill and Marcus 1992, Cutting, et al. 1992, Kupiec 1992] . These require hand-tagged corpora for training. Furthermore, the semantic properties of the words are not identified by these methods.
Finch and Chater made a substantial breakthrough in word classification by developing a "bootstrapped" procedure that needs no prior tagging and generates both syntactic and semantic classes [Finch and Chater 1992, Finch and Chater 1993] . It compares words by comparing the contexts in which they occur (the immediately surrounding words). We have extended their method and applied it to biological text [Futrelle and Gauch 1993] .
Building word classes is based on the substitution principle: If two words can be freely intersubstituted in a variety of contexts then the words are considered associated. For example, the three words in braces can be substituted freely in the context shown,
The fifth element in the long {chain, sequence, array} is ..
whereas most others cannot. This context places both syntactic and semantic restrictions on the words in the braces (singular nouns describing a discrete sequentially addressable object). Other contexts may impose only syntactic restrictions, e.g., plural noun in this example,
We knew about many of the {ideas, buildings, motions}.
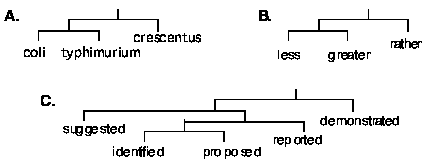
The classification method works as follows. K words are chosen for classification, normally the K highest frequency words in the corpus, e.g., K=1,000. The L highest frequency words from the corpus are chosen as the context indicators, e.g., L=150. M context words are used, e.g., M=4, including the 2 words immediately to the left of the word of interest and the 2 words immediately to the right. For each of the K words, the frequencies of the context words are accumulated from the entire corpus in a vector of size L at each of the M positions, e.g., a 4x150 vector totaling 600 elements. The vectors of the words are compared, e.g., by an inner product measure, and the two context vectors that are most similar are taken to define the two most similar words in the set of K. Those two words (and their contexts) are merged into a single item, similarities are recomputed and the process repeated. This results in a bottom-up hierarchical agglomerative clustering of the K words [Jain and Dubes 1988]. Some examples from our work are,
The results of these analyses are quite striking, considering that they use no input of information about English at all, other than the corpus itself. It is truly a "bootstrapping" technique. The key idea of the method is that word occurrences organize themselves through a process of self-consistency -- any set of word occurrence patterns that is consistent with itself defines a particular usage class of the word. A similar consistency relation between distinct words (such as "suggested" and "proposed") defines a common usage class. More technically, such a class is called a semantic field.
Another example obtained by the clustering techniques is a set of bacterial mutant names. "double" is also used as a mutant designator because some organisms carry two mutations simultaneously:
che, cheA, cheB, cheR, cheY, cheZ, double, fla, flaA, flaB, flaE, H2, hag, mot, motB, tar, trg, tsr
Still another cluster found is a set of technique designators,
microscopy, electrophoresis, chromatography
5. Problems with word classification suggest a database formulation
The clustering technique used for word classification has problems, but its potential is so great that it is worth refining. An improved algorithm makes serious demands on the system, especially in terms of the data representation used. This led us to develop a database approach to classification.
The problems of the classification method just described include:
* The multiple senses of a single word are merged so the classification is dealing with a multi-class item and cannot generate very precise results. Often it is just the most frequent meaning of a word which is chosen and the other meaning(s) is lost.
* Many words must be analyzed simultaneously for the method to work. It is difficult to focus on one or a few words.
* Special cases such as idioms are difficult to deal with because the method insists on treating each item in the same way.
This leads to a set of requirements for an improved system:
* The system should be word-based, not character-based.
* Words and their contexts should be indexed for rapid retrieval.
* Words should be able to contain rich information, including data on typical and specialized contexts, relations to other words, etc.
6. The database design
We now describe a simple prototype system that we have developed with the above requirements in mind. The fundamental idea is to treat each word as an object, and indeed, each word occurrence as an object. The text is simply a sequence of these objects. (Additional structure such as paragraphs and sentences is also included.) The entire database has been built as a collection of persistent Lisp structures (details below).
A unique integer identifier, a logical UID, is assigned to every distinct blank-separated character sequence in the corpus (no down-casing or affix stripping is done). These are assigned in accession order (in the order met), so the corpus can be added to without altering any earlier UIDs.
The persistent data structures are:
The text, represented as a sequence of 4 million UID values, the text word array.
An inverted index to every UID occurrence in the text word array. No stop- list is used, because corpus linguistic analyses need to know about occurrences of terms such as "a", "the" and "and".
A hash table is built for string - - > UID mapping and an array for UID - - > string mapping.
Similar indexes are built to map between word positions and byte positions in the original text file.
Once these data structures are in place, any word occurrence, and its context, can be obtained by random access. Similarly, if we want to know all contexts containing "genetic", they can be found using the inverted index. There is a problem however. If we want to find all contexts containing a particular sequence of context words, they will be found scattered across distinct disk pages. In our 4 million word corpus, there are about 4 million contexts. If they were all streamed in from disk in sequence, the total read time would only be a few seconds. If a distinct page access were done for each, it would take 10,000 times as long. So the ideal is to design a disk-based data structure that gives performance as close to the streaming rate as possible. This can be done by careful replication of the data, trading space for time. For each word W, all UID sequences from the corpus that have length 2M+1 and have W in the central position, are stored contiguously on disk. This increases the space requirements by a factor of 2M+1. (Actually, the middle word is not stored in each sequence but the position of the sequence in the text is stored, giving the expansion factor quoted.) This results in the replicated context sequence file.
The replicated file is simple to use. Assume we want to find all contexts such as this one that have "DNA" two positions to the left of center:
"DNA was purified by the"
We need only look up all the sequences in the replicated sequence file indexed by "DNA". These are guaranteed to be contiguous in the file and can be streamed rapidly from the disk to memory. For M=4, sequences of length 9 are stored, so that we are guaranteed that the 4 words to the right of "DNA" are contained in the data read in.
The database organization just described is a useful substrate on which to build many tools for text analysis. For example, corpus linguists often use KWIC indexes ("key word in context"). These are normally generated by batch methods, but by exploiting indexes, the system can typically respond to any specific KWIC request within a fraction of a second.
7. Using database techniques for word classification
Once the inverted index and the replicated context files are built they can be used to do a more fine-grained analysis of context similarity. One of the algorithms we are currently exploring is the following:
1. Choose a word, Wi.
2. Look up all contexts, Cij , of all Wi tokens (word occurrences). A context is typically the immediately preceding and following n words. n=2 in most of our studies.
3. Define a similarity measure Sjk between any two contexts, Cij and Cik, e.g., a position-weighted match of context words.
4. Using the similarity measure, perform clustering on the contexts, e.g., by agglomerative hierarchical clustering [Jain and Dubes 1988] .
5. Choose only well-separated clusters [Jain and Moreau 1987] of frequency > fmin and define them as a set of word uses, Un.
6. For each Un find all occurrences of the contexts or contexts that match closely enough by the context similarity metric, that occur anywhere in the corpus (with any other words, Wmn).
7. Sort the words found by frequency. The high-frequency items are reported as similar to Wi.
It is quite easy to understand this algorithm by looking at an example. Assume we explore the following context of the word "wall":
"...of cell (wall) components in...."
Other occurrences of similar contexts give rise to the set,
"envelope", "surface" and "host"
The first two are nearly synonymous with "wall". The third item, "host" would be excluded from this group when other of its contexts were analyzed in detail. Here are some of the similar contexts discovered,
its cell envelope components for
both cell envelope components affects
L cell host components by
host cell surface components has
different cell surface components within
8. Discovering the higher-order structure of language
Once word classes are found, word occurrences can be augmented by their class designators, greatly reducing the number of distinct item types in the corpus. For example, assuming that the system has discovered the higher-order classes, Art (Article) and N (noun), the underlined Art, N phrases in the following two sentences become identical and can be analyzed as a single higher-order object:
"It is the elephant."
"He was the person."
This allows a bootstrap classification method to discover constituents such as the noun phrase, inducing a rule of English grammar: NP -> N V. Similar results follow from classifications which compare items of different lengths such as,
"The big old dog was asleep."
"Fred was awake."
This establishes equivalence between the longer noun phrase and the single item.
Once the higher-level structures are found, they can be applied to the analysis of the corpus, ultimately extracting knowledge from it. For example, in biology papers, which are overwhelmingly experimental studies, most of the content consists of describing experiments and their outcome in the schematic form,
something1 was done
to something2
under some3 conditions and
something4 was observed
The approach we have outlined for discovering higher-order structure in language is in sharp contrast to the approaches of classical linguistics in which the linguist writes grammar rules based on his or her understanding of the nature of the language, and revises them as necessary. Our approach is fundamentally a reflective one in which the analysis of language uses rules that are derived directly from the structure observed in large corpora. It is a self-consistent approach that is able to take into account the structure of a particular genre while ignoring issues that do not arise in that genre. The approach is very much in the spirit of machine learning of natural language [Daelemans and Powers 1992] .
The results of these higher-order analyses are recorded in fully sequential indexes of positions or UIDs or using hash tables or B- trees for sparse information. For example, in tagging every word for part-of-speech, a 4 million element persistent byte array is used to record the tags. Another important collection of information for corpus linguistics, and for IR query restriction, is the location of sentence boundaries. These can be stored in a persistent B- tree which is ideally suited to efficient querying of such range information. A similar strategy can be used for phrasal nouns, which have arbitrary lengths and locations, e.g., for "Northern Hemisphere" or "SDS-polyacrylamide gel electrophoresis (PAGE)".
For higher level analyses, constituents such as phrases and clauses can be indexed, once computed, and are then rapidly available to participate in still higher level analysis such as frame-filling. The constituents can be indexed in range indexes such as B-trees, so they can be "seen" from anywhere within the constituent or externally. As an example of the use of such indexes, the system could return all clauses which contain a certain word pair, computed by merging the inverted indexes for the two words and the B-tree for clause locations.
9. The role of Object-Oriented databases
Even if we assume that a Digital Library is focused on static, archival documents, the demands on database technology are extensive. Object-oriented databases are more suitable to representing the complex inter-related structures within and between documents than are relational databases. However, it will be some time before we understand fully how to extract performance from OODBs that can match mature relational database systems. Here are some of the requirements that favor the use of OODBs [Bertino and Martino 1993] :
Complex, inhomogeneous and variable size data. This includes bibliographic references, numerical data including percentages and error ranges and physical units, dates and times, proper names and phrasal nouns, complex tables and mathematical expressions. There may also be higher-level structures such as SGML.
Functional relations within and among documents. An outline of a text, its table of contents, its bibliography and its index are functionally interdependent. Hypertext and citation linkages may be added long after a document is created
Support of annotations. Users must be able to annotate documents or save portions of interest to them. In corpus linguistics, we need to be able to add attributes to words and to annotate and relate higher-order constituents.
Performance. Retrieving an object could require the retrieval of thousands of other objects that are components of, or otherwise related to the object of interest. There is no single organization of secondary storage that will accommodate all retrieval requests efficiently, so additional strategies have to be developed.
Changes in database design. Since information technology is in constant flux, there is always pressure to redesign databases. Databases should support design changes, e.g., schema evolution.
Kim [Kim 1993] exposes the strengths and weaknesses of the various approaches to DB design and suggests that a multidatabase is needed for many applications. It should be readily apparent that we embrace this view, inasmuch as we use simple vectors and tabular structures for large homogeneous collections but complex interrelated objects for data about individual words.
Databases for text analysis cannot be designed top-down and in advance, because the problems of analyzing the natural language text of large corpora are too difficult. Instead, we must be satisfied with bottom- up and incremental database methods [Zdonik 1993] . In this approach, the structure of the database is revised as new insights occur and the variety and complexity of the data grows; the process is independent of whether new text is added to the database or not.
In our work we use the Wood persistent heap system that supports Macintosh Common Lisp with persistent versions of all normal heap objects (numbers, strings, lists, structures, CLOS instances) as well as purely persistent objects such as large arrays that will not fit into dynamic memory, and indexes, both B- trees and hash tables [St. Clair 1993] . Our system initially supports Ascii text with minimal markup.
The persistent components in our OODB system can be smoothly integrated into the host language using a meta-object protocol [Kiczales, et al. 1991, Paepcke 1993, Paepcke 1993] Normally, a CLOS object slot reference is a map from an instance-slotname pair to a value in the Lisp heap. Using a meta-object protocol, a slot functionality can be specified so that a slot reference maps through a persistent index and returns or sets a persistent object. This approach avoids having to define a separate data-definition language and gives us the maximum flexibility for exploratory development.
10. Information retrieval issues
Let us assume that we want to build a corpus of ten years of the world's biomedical literature containing 20 billion words and occupying 150 gigabytes (without indexes). The scale-up problems are severe.
To illustrate the problems of scaling up methods we can start by revisiting the indexing examples just discussed. The number of UIDs would be a small fraction of the total word count, even if phrasal nouns were added explicitly. Any references to word positions would require more than a 32 bit address space, so either a 64 bit architecture could be used or the address space could be factored into volume references and positions within volumes, where a volume could be one year of a periodical or a single monograph title. B-tree indexes have such high branching factors, e.g., 100, that only about four disk references would be needed to locate items anywhere in such a collection. An inverted index for "the" would contain 1 billion entries and would probably not be constructed except for small portions of the corpus for which intensive Corpus Linguistics studies were done. A stop-list would cut the inverted indexes down to a modest fraction of the size of the corpus itself, and large entries could be given B- tree structure to improve their performance beyond linear or binary search when processing conventionally restricted full text queries, e.g., occurrences of "DNA" "water" and "interact" within the same sentence.
To respond quickly to user requests, the tractability of the indexes just described is not enough. The full text query described earlier, run for all years in the collection, would require merging large inverted index arrays. Furthermore, the results might need to be sorted to give a ranked list, using frequency of occurrence of the various query items in the text. Thus, no response would appear until all merging and sorting was done, giving an initial lag in the response to the user. A better way to respond is to pipeline the processing, so that partial results of the merge are available and the sorting are available early on. This means that some good, though suboptimal ("First") results can be found for the user with negligible delay ("Fast"). Since only the highest ranked items are of interest, linear sorting techniques can be used, e.g., a one-bucket sort. This is the "First-Fast" strategy, a form of satisficing. For a discussion of these techniques, see also [Shum 1993] .
Successive deepening is a more general technique than "First-Fast" and includes it as a special case. It can be illustrated by the following scenario. Consider a digital library system in a client-server architecture that retrieves complex, formatted hypertext documents with text and graphics and delivers them to the client workstation. This might be occurring over a wide-area network. From the database point of view, the document will have a rich structure with objects denoting this structure, such as sentences, paragraphs, tables and diagrams, linkages within itself, e.g., links to bibliographic items and figures and links to external object collections such as the full articles referenced, the lexicon, other works by the same authors (whether referenced or not), etc. There may well be enough links to traverse the entire terabyte database, simply starting from one article.
Clearly, the "fully linked" article cannot be delivered to the client, because it could link to a terabyte of information. So only some of these links can be traversed in bringing in the article initially. This is done by bringing in only enough objects to display the article and bringing in successively more objects only on demand, or by the system's anticipating common user needs and caching the items in the background. A typical sequence of user actions and system responses might be the following:
A section of a document has been asked for. No information about the document other than it's identity is present in the client.
The first few screenfulls of the visual form of the text are downloaded to the client. This includes only the characters, fonts, linebreaks and low-level drawing calls for figures, the minimal amount of information needed to produce the image of the text and diagrams on the screen. Linkage objects to the next and previous screenfulls are brought in.
Normally, all the user might do is to scroll through the text. Adjacent screenfulls, visual form only, are downloaded as scrolling proceeds.
The user sees a paragraph of interest that they want to use as relevance feedback to compose a query. The user double clicks in the paragraph. The system notes the click position and only then downloads structural information so that the paragraph boundaries become known to the client, allowing the paragraph to be highlighted. The request can trigger presentation of still other documents, starting with their visual form only.
In another request, the user might ask for the outline of a document. Since outlines are typically small and the user typically asks for parts of them to be expanded, each visual line of the outline could be loaded, and in the background, its screen boundaries for cursor selection and pointers to the visual forms of the corresponding full text sections.
In Successive Deepening, it is useful to store prestructured "thin" views at various levels, on the server. In other cases the server, with full and fast access to all objects, would construct a view at the appropriate level of complexity, and send only that to the client. Otherwise interesting object-oriented approaches to information systems often do not give details of how they would handle the performance issues associated with disks and networks [Cutting, et al. 1991] .
11. Conclusions
We have used techniques from current information retrieval, especially inverted indexes, and from object-oriented databases, especially the strategy of selective pointer following, to describe how future systems for information retrieval and corpus linguistics can be built. In particular, we have described our ongoing system development aimed at building a research and development environment for corpus linguistics. These studies can in turn form the foundation for the intelligent digital library systems of the future.
Acknowledgments
This work was supported in part by a grant from the National Science Foundation, IRI-9117030 and a Fulbright Senior Scholar grant for research in the United Kingdom (to RPF). Thanks to Claire Cardie and Scott Miller for comments.
References
[1] Baeza-Yates, R. A. 1992, String Searching Methods, in Information Retrieval : Data Structures and Algorithms, Frakes, W. B. and R. Baeza-Yates, Editor. 1992. pp. 219-240. Englewood Cliffs, New Jersey: Prentice Hall.
[2] Bertino, E. and L. Martino 1993, Object-Oriented Database Systems. Reading, MA: Addison-Wesley.
[3] Brill, E. 1992. A Simple Rule-Based Part of Speech Tagger. In Proc. 3rd Conf. on Applied Natural Language Processing. 1992, pp. 152-155. Trento, Italy. Assoc. for Computational Linguistics.
[4] Brill, E. and M. Marcus 1992. Tagging an Unfamiliar Text with Minimal Human Supervision. In AAAI Fall Symposium Series: Probabilistic Approaches to Natural Language (Working Notes). 1992, pp. 10-16. Cambridge, MA.
[5] Church, K. W. and R. L. Mercer 1993. Introduction to the Special Issue on Computational Linguistics Using large Corpora. Computational Linguistics. Vol. 19(1), pp. 1-24.
[6] Cutting, D., J. Kupiec, J. Pedersen and P. Sibun 1992. A Practical Part-of-Speech Tagger. In Proc. 3rd Conf. on Applied Natural Language Processing. 1992, pp. 133-140.
[7] Cutting, D., J. Pedersen and P.-K. Halvorsen 1991. An Object-Oriented Architecture for Text Retrieval. In RIAO-91. 1991, pp. 285-298.
[8] Daelemans, W. and D. Powers 1992, ed. Background and Experiments in Machine Learning of Natural Language: Proceedings of the First SHOE Workshop. Tilburg, The Netherlands: Institute for Language Technology and AI, Tilburg Univ.
[9] Finch, S. and N. Chater 1992. Bootstrapping Syntactic Categories Using Statistical Methods. In Proc. 1st SHOE Workshop. 1992, pp. 229-235. Tilburg U., The Netherlands.
[10] Finch, S. and N. Chater 1993, Learning Syntactic Categories: A Statistical Approach, in Neurodynamics and Psychology, Oaksford, M. and G. Brown, Editor. 1993. pp. 295-319. San Diego, CA: Academic Press.
[11] Futrelle, R. P. and S. Gauch 1993. Experiments in syntactic and semantic classification and disambiguation using bootstrapping. In Acquisition of Lexical Knowledge from Text. 1993, pp. 117-127. Columbus, OH. Assoc. Computational Linguistics.
[12] Gonnet, G. H., R. A. Baeza-Yates and T. Snider 1992, New Indices for Text: PAT Trees and PAT Arrays, in Information Retrieval, Frakes, W. B. and R. Baeza-Yates, Editor. 1992. pp. 66-82. Prentice Hall.
[13] Jacobs, P. and L. F. Rau 1993. Innovations in text interpretation. Artificial Intelligence. Vol. 63(October 1993), pp. 143-191.
[14] Jain, A. K. and R. C. Dubes 1988, Algorithms for Clustering Data. Prentice Hall Advanced Reference Series, Englewood Cliffs, NJ: Prentice Hall.
[15] Jain, A. K. and J. V. Moreau 1987. Bootstrap Technique in Cluster Analysis. Pattern Recognition. Vol. 20(5), pp. 547-568.
[16] Kiczales, G., J. des Rivieres and D. G. Bobrow 1991, The Art of the Metaobject Protocol. Cambridge, MA: MIT Press.
[17] Kim, W. 1993. Object-Oriented Database Systems: Promises, Reality, and Future. In International Conference on Very Large Data Bases. 1993, pp. 676-687. Dublin, Ireland.
[18] Kupiec, J. 1989. Augmenting a hidden Markov model for phrase dependent word tagging. In DARPA Speech and Natural Language Workshop. 1989, pp. 92-98. Cape Cod MA.
[19] Kupiec, J. 1992. Robust part-of-speech tagging using a hidden Markov model. Computer Speech and Language. Vol. 6,pp. 225-242.
[20] Loeffen, A. 1994. Text Databases: A Survey of Text Models and Systems. SIGMOD RECORD. Vol. 23(1), pp. 97-106.
[21] Paepcke, A. 1993, ed. Object-oriented Programming: The CLOS Perspective. Cambridge, MA: MIT Press.
[22] Paepcke, A. 1993, User-level language crafting: Introducing the CLOS Metaobject Protocol, in Object-oriented Programming: The CLOS Perspective, Paepcke, A., Editor. 1993. pp. 65-99. Cambridge, MA: MIT Press.
[23] Ritchie, G. D., G. J. Russell, A. W. Black and S. G. Pulman 1992, Computational Morphology - Practical Mechanisms for the English Lexicon. Cambridge, MA: The MIT Press.
[24] Salton, G. 1989, Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer. Reading, MA: Addison-Wesley Pub. Co.
[25] Shum, C.-D. 1993. Quick and Incomplete Responses: The Semantic Approach. In CIKM : Second International Conference on Information and Knowledge Management. 1993, pp. 39-48. Washington, DC, USA. ACM Press.
[26] Sproat, R. 1992, Morphology and Computation. Cambridge, MA: The MIT Press.
[27] St. Clair, B. 1993. In[[??]] WOOD (William's Object Oriented Database) Documentation. (cambridge.apple.com, 1993). Available through Internet ftp.
[28] Zdonik, S. B. 1993. Incremental Database Systems: Database from the Ground Up. In SIGMOD. 1993, pp. 408-412. Washington, DC.
[29] Zernik, U. 1991, ed. Lexical Acquisition: Exploiting On-Line Resources to Build a Lexicon. Hillsdale, NJ: Lawrence Erlbaum Assocs.
[30] Zernik, U. 1991, Train1 vs. Train2: Tagging Word Senses in Corpus, in Lexical Acquisition: Exploiting On-Line Resources to Build a Lexicon, Zernik, U., Editor. 1991. pp. 97-112. Hillsdale, New Jersey: Lawrence Erlbaum Associates, Publishers.
[31] Zobel, J., A. Moffat and R. Sacks-Davis 1993. Searching Large Lexicons for Partially Specified Terms using Compressed Inverted Files. In 19th International Conference on Very Large Data Bases. 1993, pp. 290-301. Dublin, Ireland. Morgan Kaufmann Publishers, Inc.